Descriptive Modeling
The work in this area studies the interrelationships between different variables or processes within the same subsystem and interactions among multiple subsystems to gain a better understanding of the behavior of the climate system. In particular, climate data, be it observed or model-simulated, has complex dependencies across space as well as time. These dependencies can be local in nature, thus involving spatial and temporal units in a neighborhood, or there may be long range teleconnections and long memory time series effects. One way to capture these relationships and dependencies is with complex networks or descriptive data mining approaches, such as clustering. Another approach is to capture various features of these dependencies through statistical modeling, estimation, testing, and inference. To this end, Bayesian, empirical Bayes and resampling-based techniques of inference are studied. Regardless of approach, this broad class of research activities will feed into other parts of the project, primarily into predictive modeling.
Highlights:
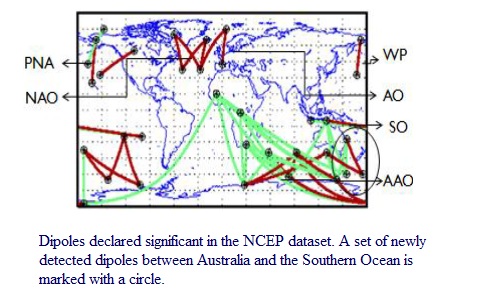
One project has developed techniques based on complex networks to find climate dipoles, i.e., pairs of regions on the surface of the Earth whose behavior has significant impact on the global climate. Novel aspects of this work are network patterns whose edges involve negative correlations and the use of reciprocal nearest neighbor pruning to eliminate irrelevant edges from the network. More recently, the dipole finding approach was extended to address the issue of the statistical significance of the patterns discovered and to take into account time lags, i.e., the fact that events in one part of the climate system can have a delayed impact on the rest of the climate system. The dipole work has identified a new climate dipole that is the result of a relationship between the Antarctic and Southern Oscillations. This new finding allows for a much more detailed description of relationships between climate, especially over the populated regions of southeastern Australia and northern New Zealand. The dipole work is also being used to evaluate and compare General Circulation Models (GCMs) of the latest generation - the Climate Model Intercomparison Project phase 5 (CMIP5) - in terms of how well they reproduce known climate phenomena.
Other work has focused on using complex networks to identify the structure of climatological data on a decadal scale to identify major climatological shifts (or regime changes) using one or more climate variables. By applying this technique to the output of GCMs, we hope to be able to anticipate such regime shifts in the future evolution of the climate system. Indeed, we recently performed an extensive climate model intercomparison using model outputs from the Climate Model Intercomparison Phase 3 (CMIP3) archive, which formed the basis for much of the Fourth Assessment Report (AR4) of the Intergovernmental Panel on Climate Change (IPCC) and will continue to be used for the Fifth Assessment Report. We find that, with the possible exception of the geopotential height field, consistency across the other variables is questionable. More importantly, none of the models comes close to matching the observed dynamics (NCEP Reanalysis). This is a significant finding especially for the temperature and precipitation fields, which are widely used to produce future projections and in turn for planning and policy making decisions. This work is published in Climate Dynamics, one of the top climate journals, and contains details of the analysis and an extended discussion.
We have also conducted research in complex networks to enable hypothesis-driven insights regarding the intricate interplay between the topology and dynamics of a physical system at different scales. In complex networks, anomalous communities, or dense sub-networks that are conserved within one group of networks but undergo statistically significant structural transformation in the other groups of networks, are candidate structures for explaining physical basis underlying group-related extreme events. By constructing different groups of networks based on physical system phases, e.g., high or low hurricane activity, the approach yielded 8-16% accuracy increase in terms of various skills for two important extreme event problems-identification of tropical cyclone-related and of African Sahel rainfall related climate indices.
Mesoscale ocean eddies (hereafter eddies) are coherent rotating structures of ocean spanning tens to hundreds of kilometers and lasting a few days to several months, and are critical phenomena for understanding the world's oceans as they dominate the ocean's kinetic energy and are responsible for the transport of heat, salt, nutrients, and energy across the oceans. Our research attempts to address major limitations in both the quality of eddy features identified and the eddy tracks that result from monitoring such features. This research has introduced two novel methodologies to identify and track noisy features in a continuous spatio-temporal field. Our method was able to resolve more coherent features than the most-widely used method in the literature and will allow us to provide the oceanography community with more accurate ocean eddy statistics. For tracking features, we introduced the concept of multiple hypothesis assignment (MHA), which where features are assigned to multiple potential tracks, and the ?nal assignment is deferred until more data are available to make a relatively unambiguous decision. All computer code is available for free as an open source project. Recently, this project produced the first comprehensive global mesoscale ocean eddy dataset which can be used for other scientific inquiries such as the impact of eddies on marine primary production. All data, including 10 million eddy features, source code, and an interactive eddy viewer are available at http://ucc.umn.edu/eddies.
A project related to hurricanes is investigating predictive features which contribute to the development of a cloud cluster (CC) into a tropical cyclone (TC) without using numerical weather prediction models. To address the imbalanced class nature of this problem, we developed a selective clustering based oversampling technique (SCOT) which addresses data imbalance in a selective manner.
People: Agrawal, Choudhary, Chatterjee, Ganguly, Hendrix, Kumar, Liess, Samatova, Semazzi, Steinbach, Steinhaeuser