Discovering Patterns of Change
Climate and environmental data are characterized by various types of change including periodic patterns, subtle trends and major shifts. Hence, the automatic detection of changes in large spatio-temporal datasets is important to monitoring and understanding the behavior of the global climate system. Positive feedbacks inherent in the climate system are often responsible for such climatic changes. For example, prolonged droughts and pluvial events in the 20th century have contributed to large-scale famine and the displacement of millions of people who live off the land. Extremes in temperature also have an influence, especially when coupled to abrupt precipitation changes. In the 20th century there have been numerous abrupt climatic changes - some whose periodicities are well documented. As we move forward in the 21st century with a warming world that has poorly understood non-linear behavior, it is critical that we improve understanding of abrupt climate changes and enhance forecasting of their onset and duration. Our work in the area of change detection and analysis include wavelet and graphical model based approaches for abrupt change detection, statistical methods for change detection with complex dependency patterns, land cover change detection and characterization, and analysis of geospatial uncertainty patterns from global climate models. To that end,we have investigated various machine learning and statistical approaches to change detection.
Highlights:
The automatic detection of changes in large spatio-temporal datasets is important to monitoring and understanding the behavior of the global climate system. One project considered major droughts, which are persistent over space and time. We formulated the problem of drought detection as a Maximum-a-Posteriori (MAP) inference problem on a Markov Random Field (MRF), and developed an efficient MRF based drought detection algorithm. MAP inference based drought detection has been shown to find almost all major droughts in the past century and many lesser-known significant droughts. In year 3, we implemented the Bethe-ADMM algorithm using MPI and showed almost linear speedup up to 1024 MPI processes with low communication cost.
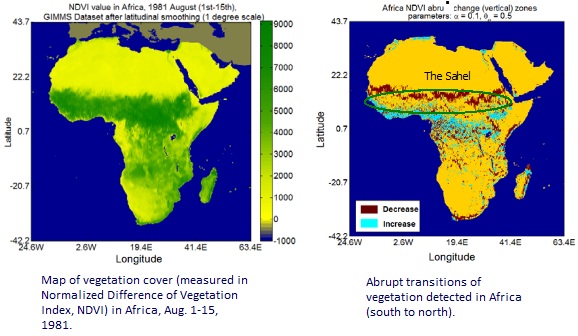
A couple of other approaches with a more algorithmic flavor have also been developed for change detection. In the first approach, we developed two algorithms: Abrupt Change Interval Miner (ACIM) and Sub-path Enumeration and Pruning (SEP) for the discovery of interesting spatio-temporal sub-paths/intervals, such as those with abrupt changes. These algorithms find abrupt changes that occur in geographical space, indicating sharp transitions regions of environment between different ecological zones. In year 3, theoretical analysis showed that the SEP-TKDE algorithm is correct and complete. Its memory cost is O(1), much cheaper than O(n2) in the previous SEP top-down method. In year 4, we generalized the change footprint patterns to persistent change windows (i.e., regions of persistent change over a time period) and formalized the problem of persistent change windows (PCW) discovery.
In the second approach, we are exploring non-stationary time series clustering to identify persistent climate regimes and construct a dynamical model for each regime. In this work, we are generalizing time series clustering based on finite elements method (FEM), a newly developed technique that can find regimes without any explicit assumptions on data distributions. In year 3, we applied FEM-clustering of surface temperature across North Carolina from 1950 to 2010 for 60 years, and investigated relationship between these trends and important climatic indices. In year 4, the method is extended to find optimal number of change points by the information theory criterion, and is applicable to new applications such as modeling non-stationary Gaussian and Poisson distributions and vector autoregressive models.
Remote sensing datasets provide an opportunity for monitoring crucial ecosystem resources, such as the health of forests or the extent of in-land water bodies, by capturing information about a wide variety of ecosystem variables, such as land surface temperature and optical surface reflectance, at a global scale and in a timely fashion. As an example, learning the relationship between land surface temperature and the amount of forest cover at a location can be useful for monitoring the health of forests and the impacts of disturbances such as deforestation and logging. However, this is challenging due to the presence of heterogeneity in the data due to the presence of multiple geographies, seasons, climatic zones, types of vegetation, etc., each inducing a different heterogeneous distribution in the data instances. We proposed an approach that consists of the following key steps: (a) partitioning the heterogeneous dataset into relatively homogeneous data partitions in adherence to the distribution of vegetation types, (b) extracting the structure among the data partitions using similarity in vegetation types, and (c) utilizing the structure among the partitions for regularizing the learning of a predictive model at each data partition. By conducting a series of experiments to evaluate the performance of our proposed framework in comparison with the baseline approaches, we were able to show that our method: (a) captures meaningful information about the heterogeneity in the data, (b) improves the prediction performance in the presence of data heterogeneity, (c) is robust to over-fitting in scenarios with limited training data, and (d) is robust to the choice of the number of partitions used to represent the heterogeneity in the data.
In other work using remote sensing data, we developed novel spatio-temporal data mining algorithms that can be used to produce cost-effective and reliable burned area maps from remotely sensed MODIS data. The use of classifiers to detect extremely rare events such as fires is subject to a well-known limitation, i.e., a classifier with accuracy as high as 99% would still have a low precision of event detection, which limits the applicability of classification models for event detection. To address this challenge, we proposed a region-based event mapping approach that combines the output from multiple classifiers based on different features and leverages the spatial context of burned areas to produce a more accurate and exhaustive burned area map. We have created a database of all the historical fires in the last decade across the globe using the proposed burned area mapping algorithm and have shown that compared with other standard techniques our approaches consistently performs better in terms of precision and recall.
Mapping urban extent and growth has traditionally been performed by first building a classifier on remote sensing data using manually selected training samples to assign a land cover class from a finite set of classes to every pixel based on observed spectral values (the feature space). When a new image arrives for the latest time step, this classification process is repeated and every pixel is re-assigned to a land cover class based on its current spectral values. To identify changes in the urban extent that occurred between any two given years, the classified maps of those years are compared. However, satellite data has unique characteristics that make classification difficult and the resultant accuracy is not sufficient for end users who want to study urban change dynamics. To overcome this challenge, we have explored an innovative data mining approach to improve the class labels (associated with pixels) in multi-temporal land cover maps. Our main intuition is to exploit the rich contextual information present in the temporal sequence of class labels which is not used by the classifier while generating class labels for images from different time steps. We applied our technique on classification maps generated using classifiers trained on Landsat data in several cities in Brazil. Our results demonstrate that the new classification maps generated by including the temporal context reduce the spurious changes due to classification errors in the original classification maps.
People: Banerjee, Chatterjee, Ganguly, Homaifar, Kumar, Liess, Shekhar, Snyder